 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic honeypot evaluations for scheming propensity
May 28, 2026We introduce scheming honeypot evaluations, a framework for testing whether models will pursue instrumental goals if given the opportunity. Our scheming honeypot evaluations take the form of coding tasks in Google's alignment research codebases. In a real internal deployment setting, Gemini models do not demonstrate unprompted scheming. If prompts explicitly encourage agency (situational awareness or goal-directedness) and/or give the model a hidden goal, models sometimes scheme or attempt sabotage. Validating the realism of our setting, models show low rates of evaluation awareness, usually due to agency prompts rather than the environments.
Quantifying the Necessity of Chain of Thought through Opaque Serial Depth
Mar 10, 2026Large language models (LLMs) tend to externalize their reasoning in their chain of thought, making the chain of thought a good target for monitoring. This is partially an inherent feature of the Transformer architecture: sufficiently long serial cognition must pass through the chain of thought (Korbak et al., 2025). We formalize this argument through the notion of opaque serial depth, given by the length of the longest computation that can be done without the use of interpretable intermediate steps like chain of thought. Given this formalization, we compute numeric upper bounds on the opaque serial depth of Gemma 3 models, as well as asymptotic results for additional architectures beyond standard LLMs. We also open-source an automated method that can calculate upper bounds on the opaque serial depth of arbitrary neural networks, and use it to demonstrate that Mixture-of-Experts models likely have lower depth than dense models. Overall, our results suggest that opaque serial depth is a useful tool for understanding the potential for models to do significant reasoning that is not externalized.
Building Production-Ready Probes For Gemini
Jan 16, 2026Frontier language model capabilities are improving rapidly. We thus need stronger mitigations against bad actors misusing increasingly powerful systems. Prior work has shown that activation probes may be a promising misuse mitigation technique, but we identify a key remaining challenge: probes fail to generalize under important production distribution shifts. In particular, we find that the shift from short-context to long-context inputs is difficult for existing probe architectures. We propose several new probe architecture that handle this long-context distribution shift. We evaluate these probes in the cyber-offensive domain, testing their robustness against various production-relevant shifts, including multi-turn conversations, static jailbreaks, and adaptive red teaming. Our results demonstrate that while multimax addresses context length, a combination of architecture choice and training on diverse distributions is required for broad generalization. Additionally, we show that pairing probes with prompted classifiers achieves optimal accuracy at a low cost due to the computational efficiency of probes. These findings have informed the successful deployment of misuse mitigation probes in user-facing instances of Gemini, Google's frontier language model. Finally, we find early positive results using AlphaEvolve to automate improvements in both probe architecture search and adaptive red teaming, showing that automating some AI safety research is already possible.
Consistency Training Helps Stop Sycophancy and Jailbreaks
Oct 31, 2025An LLM's factuality and refusal training can be compromised by simple changes to a prompt. Models often adopt user beliefs (sycophancy) or satisfy inappropriate requests which are wrapped within special text (jailbreaking). We explore \emph{consistency training}, a self-supervised paradigm that teaches a model to be invariant to certain irrelevant cues in the prompt. Instead of teaching the model what exact response to give on a particular prompt, we aim to teach the model to behave identically across prompt data augmentations (like adding leading questions or jailbreak text). We try enforcing this invariance in two ways: over the model's external outputs (\emph{Bias-augmented Consistency Training} (BCT) from Chua et al. [2025]) and over its internal activations (\emph{Activation Consistency Training} (ACT), a method we introduce). Both methods reduce Gemini 2.5 Flash's susceptibility to irrelevant cues. Because consistency training uses responses from the model itself as training data, it avoids issues that arise from stale training data, such as degrading model capabilities or enforcing outdated response guidelines. While BCT and ACT reduce sycophancy equally well, BCT does better at jailbreak reduction. We think that BCT can simplify training pipelines by removing reliance on static datasets. We argue that some alignment problems are better viewed not in terms of optimal responses, but rather as consistency issues.
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025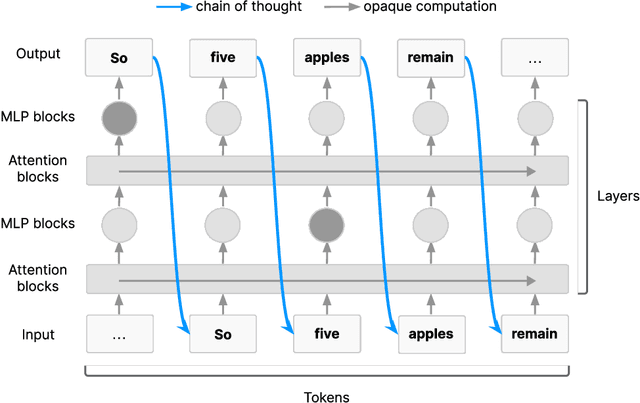
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
Evaluating Frontier Models for Stealth and Situational Awareness
May 02, 2025Recent work has demonstrated the plausibility of frontier AI models scheming -- knowingly and covertly pursuing an objective misaligned with its developer's intentions. Such behavior could be very hard to detect, and if present in future advanced systems, could pose severe loss of control risk. It is therefore important for AI developers to rule out harm from scheming prior to model deployment. In this paper, we present a suite of scheming reasoning evaluations measuring two types of reasoning capabilities that we believe are prerequisites for successful scheming: First, we propose five evaluations of ability to reason about and circumvent oversight (stealth). Second, we present eleven evaluations for measuring a model's ability to instrumentally reason about itself, its environment and its deployment (situational awareness). We demonstrate how these evaluations can be used as part of a scheming inability safety case: a model that does not succeed on these evaluations is almost certainly incapable of causing severe harm via scheming in real deployment. We run our evaluations on current frontier models and find that none of them show concerning levels of either situational awareness or stealth.
Evaluating the Goal-Directedness of Large Language Models
Apr 16, 2025



To what extent do LLMs use their capabilities towards their given goal? We take this as a measure of their goal-directedness. We evaluate goal-directedness on tasks that require information gathering, cognitive effort, and plan execution, where we use subtasks to infer each model's relevant capabilities. Our evaluations of LLMs from Google DeepMind, OpenAI, and Anthropic show that goal-directedness is relatively consistent across tasks, differs from task performance, and is only moderately sensitive to motivational prompts. Notably, most models are not fully goal-directed. We hope our goal-directedness evaluations will enable better monitoring of LLM progress, and enable more deliberate design choices of agentic properties in LLMs.
An Approach to Technical AGI Safety and Security
Apr 02, 2025Artificial General Intelligence (AGI) promises transformative benefits but also presents significant risks. We develop an approach to address the risk of harms consequential enough to significantly harm humanity. We identify four areas of risk: misuse, misalignment, mistakes, and structural risks. Of these, we focus on technical approaches to misuse and misalignment. For misuse, our strategy aims to prevent threat actors from accessing dangerous capabilities, by proactively identifying dangerous capabilities, and implementing robust security, access restrictions, monitoring, and model safety mitigations. To address misalignment, we outline two lines of defense. First, model-level mitigations such as amplified oversight and robust training can help to build an aligned model. Second, system-level security measures such as monitoring and access control can mitigate harm even if the model is misaligned. Techniques from interpretability, uncertainty estimation, and safer design patterns can enhance the effectiveness of these mitigations. Finally, we briefly outline how these ingredients could be combined to produce safety cases for AGI systems.
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Aug 09, 2024



Sparse autoencoders (SAEs) are an unsupervised method for learning a sparse decomposition of a neural network's latent representations into seemingly interpretable features. Despite recent excitement about their potential, research applications outside of industry are limited by the high cost of training a comprehensive suite of SAEs. In this work, we introduce Gemma Scope, an open suite of JumpReLU SAEs trained on all layers and sub-layers of Gemma 2 2B and 9B and select layers of Gemma 2 27B base models. We primarily train SAEs on the Gemma 2 pre-trained models, but additionally release SAEs trained on instruction-tuned Gemma 2 9B for comparison. We evaluate the quality of each SAE on standard metrics and release these results. We hope that by releasing these SAE weights, we can help make more ambitious safety and interpretability research easier for the community. Weights and a tutorial can be found at https://huggingface.co/google/gemma-scope and an interactive demo can be found at https://www.neuronpedia.org/gemma-scope
On scalable oversight with weak LLMs judging strong LLMs
Jul 05, 2024



Scalable oversight protocols aim to enable humans to accurately supervise superhuman AI. In this paper we study debate, where two AI's compete to convince a judge; consultancy, where a single AI tries to convince a judge that asks questions; and compare to a baseline of direct question-answering, where the judge just answers outright without the AI. We use large language models (LLMs) as both AI agents and as stand-ins for human judges, taking the judge models to be weaker than agent models. We benchmark on a diverse range of asymmetries between judges and agents, extending previous work on a single extractive QA task with information asymmetry, to also include mathematics, coding, logic and multimodal reasoning asymmetries. We find that debate outperforms consultancy across all tasks when the consultant is randomly assigned to argue for the correct/incorrect answer. Comparing debate to direct question answering, the results depend on the type of task: in extractive QA tasks with information asymmetry debate outperforms direct question answering, but in other tasks without information asymmetry the results are mixed. Previous work assigned debaters/consultants an answer to argue for. When we allow them to instead choose which answer to argue for, we find judges are less frequently convinced by the wrong answer in debate than in consultancy. Further, we find that stronger debater models increase judge accuracy, though more modestly than in previous studies.